
El desarrollo de modelos de Machine Learning (ML) radicional consume muchos recursos, que requieren conocimiento y tiempo significativos para generar y comparar docenas de modelos. Gracias al aprendizaje automático automatizado, se reduce el tiempo necesario para obtener modelos de aprendizaje listos para producción con gran eficiencia y facilidad.
El flujo de procesos estándar en la ciencia de datos (pipeline) consiste en el preprocesamiento de datos, la extracción de parámetros de representativos del negocio a modelar, la optimización de hiperparámetros de los algoritmos y debe ser realizado manualmente por expertos en ciencia de datos. En comparación, la adopción de AutoML permitiría un proceso de desarrollo más simple mediante el cual unas pocas líneas de código pueden generar el código necesario para comenzar a desarrollar un modelo de aprendizaje automático.
Para los equipos de ciencia de datos que trabajan con Python como es el caso de lantek, existen gran cantidad de librerías open source disponibles libremente como Lale de IBM, que ofrece una biblioteca semiautomática que se integra perfectamente dentro de las pipelines de scikit-learn, auto-sklearn u otras como TPOT o nni de Microsoft (todas ellas opensource).
Se puede pensar en AutoML como un concepto de modelizado por fuera bruta, con algoritmos de búsqueda especializados para encontrar las soluciones óptimas para cada pieza del flujo de procesos de la ciencia de datos. AutoML promete un futuro donde el aprendizaje automático democratizado es una realidad.
Así AutoML suena como una panacea en la aplicación de ML que una organización puede utilizar para reemplazar a los científicos de datos, pero en realidad su uso requiere de estrategias inteligentes adaptados a los distintos procesos que se realizan en la producción de piezas de metal por corte de chapa. Entonces, ¿cómo pueden empresas hacer uso de AutoML para optimizar su uso del tiempo y acortar el tiempo para obtener valor de sus modelos?
El flujo de trabajo óptimo para incluir AutoML, también para el sheetmetal, consiste en paralelizar cargas de trabajo en distintos algoritmos específicos y acortar el tiempo dedicado a tareas de uso intensivo. En lugar de pasar días en el ajuste de los hiperparámetros y selección de los parámetros más adecuados al objetivo buscado, un científico de datos podría automatizar este proceso en varios tipos de modelos simultáneamente y, posteriormente, probar cuál era el más adecuado.
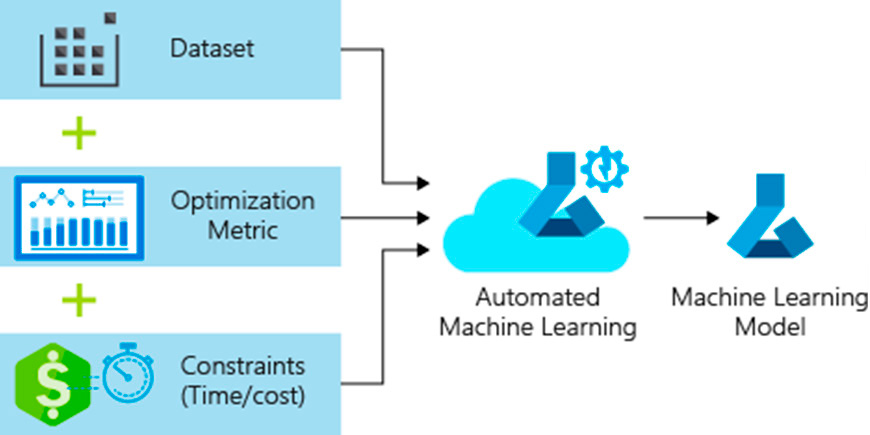
Para ello se añaden al AutoML algoritmos adaptados donde se potencian los parámetros relacionados, en el caso del sheetmetal, con la generación de chatarra, el tiempo de corte, el tiempo de entrega, parámetros de corte, tecnologías de corte, precio del material y otros parámetros de ingeniería que aportan conocimiento específico del mundo del corte de chapa en los algoritmos de ML
Así, un analista de datos sin experiencia en el sector podría aprovechar esta herramienta de AutoML adaptada para entrenar un modelo predictivo utilizando los datos que son capaces de extraer por su cuenta desde el datalake a través de una consulta. Con AutoML, un analista de datos puede reprocesar datos, crear un pipeline de aprendizaje automático y producir un modelo totalmente entrenado que se puede usar para validar sus propias hipótesis sin requerir la atención de un equipo completo de ciencia de datos y de los expertos en el negocio. Todo el conocimiento sobre corte de chapa necesario estaría en los algoritmos adaptados por Lantek.
Hasta aquí la teoría, pero ¿cuál es la realidad de la aplicación de AutoML en un caso real de LanteK? AutoML en nuestro caso proporciona lo que llamamos el baseline desde los que empezar a desarrollar nuevos modelos. Las capacidades actuales de AutoML automatizan solo una pequeña parte de las cargas de trabajo del científico de datos y del ingeniero de ML. El equipo de ciencias de datos puede acortar su tiempo de desarrollo con sus capacidades predictivas comenzando con un conjunto de prototipos para modelos de aprendizaje, simplifica la ingeniería automatizada de características, la optimización automatizada de hiperparámetros y la selección de modelos de aprendizaje automático.
El equipo de científicos de datos y analistas de datos pueden evaluar sus hipótesis, y certificar la validez de sus modelos más rápidamente, pero no se puede decir que automatiza todo el proceso, por ahora acelera el proceso de generación de modelos y podemos decir que facilita la estandarización en el desarrollo de los modelos para el sheetmetal, a la vez que reduce la curva de aprendizaje del científico de datos en el mundo del corte de chapa.

